Deep Learning概論
はじめに
「Deep Learningとは何か?」
一言でいえば、それは、
「ある定められた”多少曖昧でも構わない入力データ”に対して、”概ね期待する結果データ”を高い精度で得るための技術」
ということになります。
- ”多少曖昧でも構わない入力データ”
- ”概ね期待する結果データ”
という部分が重要なポイントになります。
AIとは
AIはArtificial Intelligenceの略で、人工知能と和訳されます。 人工知能とはなんでしょうか。
-
1. 自動運転搭載車
-
2. 自動会話ロボット
-
3. テレビゲームコンピュータ対戦
-
4. ATM
-
5. 自動計算機(電卓)
-
6. 自動ドア
これらすべて、特にユーザーが指示を出さなくても宜しく動作するという共通点はありますので、広い意味でこれらはみなある種の"知能"を持っているとみなせなくもありません。
これらは全て人の知能が行っている行動モデルに当てはめることが可能です。
人は通常、目、耳、肌、舌、鼻により視覚、聴覚、触覚、味覚、臭覚の5感を、インプットとしての情報として取得し、意識的もしくは無意識的判断をして、脳からの命令により筋肉を動かして行動をします。
上記1.~6.に対して同様に抽象化モデルを考えると、これらは、
カメラ、赤外線センサー、マイク、キーボード、タッチパネルが情報を捉え反応し、電気信号に形を変え、電子回路をとおして、モーターを動かしたり、LEDを光らせたり、スピーカーから音を出したりという形で出力します。
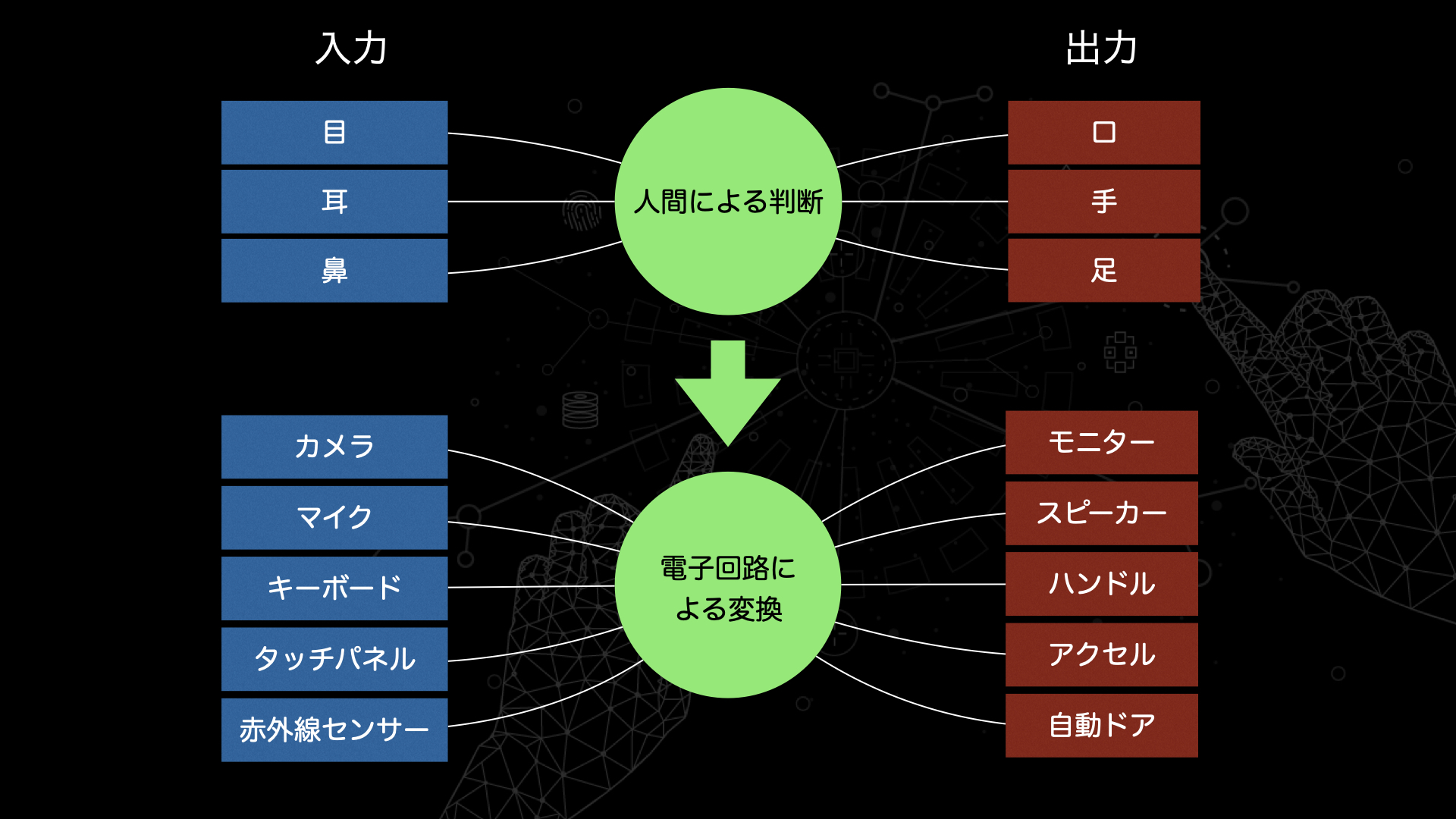
このように、
- 情報を入力
- 情報を変換
- 情報を出力
という形にまで抽象化すると、1.~6. の全ての機器を人の知能と同じモデルで捉えることができ、その意味においてすべて広い意味でのAIということも可能かと思います。
しかし、1.~6. の機器は、それぞれ違う方式により情報を変換しており、これらの方式の違いにより"AI"を分類分けすることが可能です。
まず、1.~6.の機器全てが入力電気信号をなんらかの形で出力電気信号に変換をします。
この変換に使う回路が専用回路か汎用回路に分けることができます。
専用回路は文字どおり専用に作られているため、その回路だけでその機器のもつ機能をはたすことができます。
汎用回路はパソコン等に使われるCPUを意味します。パソコンは様々なソフトをインストールすることでさまざまな機能をはたすことが可能になります。
このソフトウェアもまた専用ソフトと汎用ソフトに分けることが可能です。
このような分類分けをすると
1.、2. → A:汎用回路、汎用ソフト
3.、4. → B:汎用回路、専用ソフト
5.、6. → C:専用回路
という具合に分類分けが可能です。
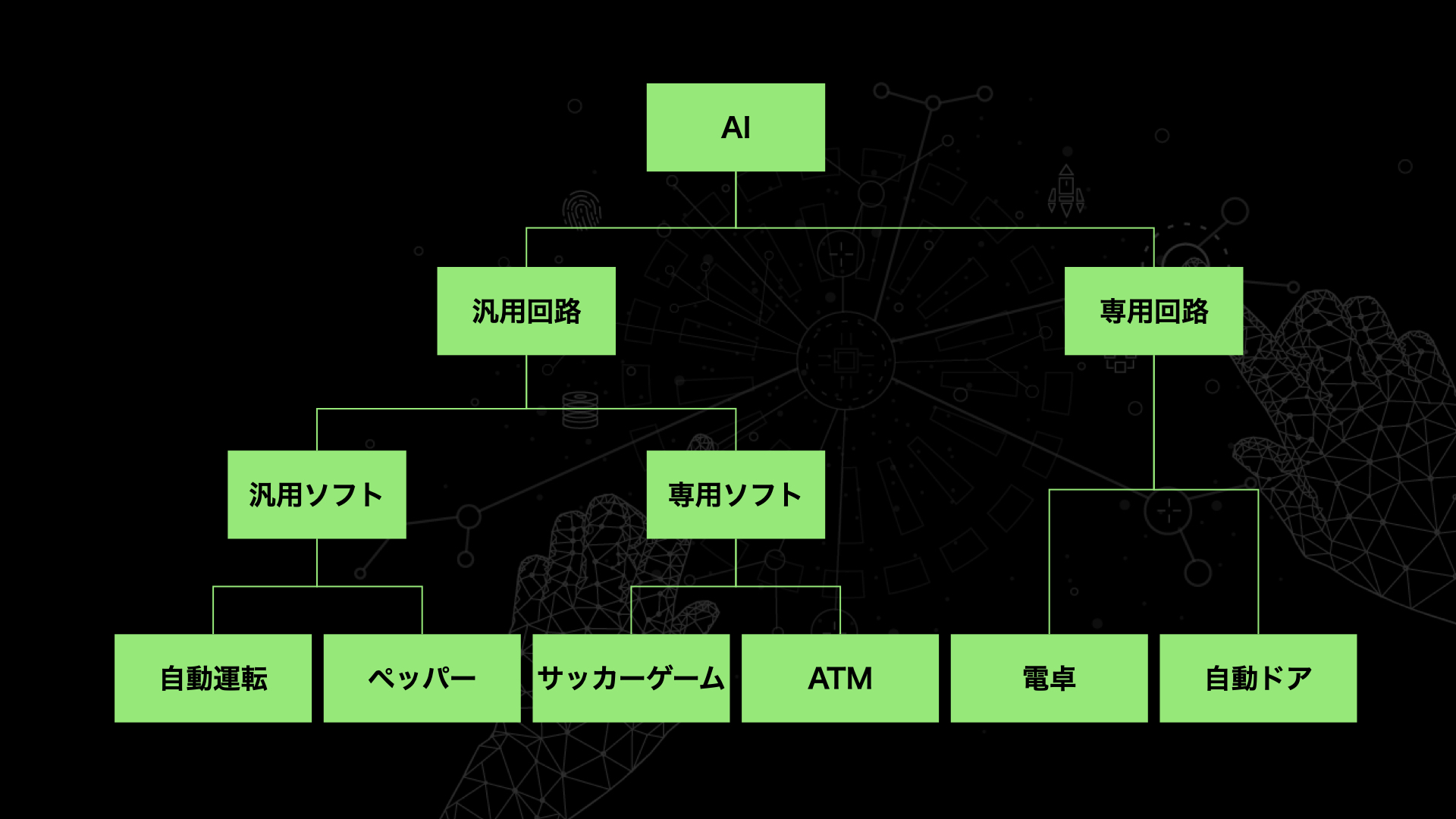
これらA.、B.、C.の違いは主に対応できる入力データの柔軟性に現れます。
汎用回路はハードウェアで機能を実現するため処理速度においては優位に動作しますが、入力データは極めて限定的です。
専用回路はソフトウェアを書くことできるので、対応できる入力データのバリエーションは格段に上がりますので、よりインテリジェントな処理が可能になります。
どんな入力データであったとしても、それに対応するロジック(関数)を書くことができれば、理屈としてはあらゆるデータのパターンに対応できます。
問題はあまりにも多い入力データのバリエーションがある場合には、有限時間内にプログラマーがロジック(関数)を書くことができないということになってしまうことです。
そこで新たなパラダイムである汎用ソフト(ニューラルネットワーク関数)、いわゆるディープラーニングの出番というわけです。
演繹的AIと帰納的AI
専用ソフトは予め明確に決められた入力データのパターンに対して、明確に決められたロジック仕様に演繹的にプログラムを積み上げていくという点で演繹的ソフトウェアと呼ぶことができます。
一方、汎用ソフトはロジック仕様を明確に定める代わりに、大量の入出力のデータパターンを与えて、それに親しい結果を返すことができる関数を帰納的に作り出すという点で帰納的ソフトウェアと呼ぶことができます。。
演繹的AIの特徴としては、入力データの形が極めて限定的であるという点があります。そして、これらの限定的なデータのパターンに対して、プログラマー(もしくは論理回路エンジニア)が網羅的に出力データを算出するプログラム(もしくは論理回路)を用意することで、次の動作を決めるという共通の特徴を持っています。このプログラムは用途により異なり、上記5つの例でいえば、5つの別々のプログラムをプログラマーが事前に作成しなければなりません。入力データに対応する出力データを導き出すロジックを明確にする必要があります。プログラムが入力データに対応する出力データを演繹的に導き出さなければならないからです。
一方、帰納的AIは、入力データの形をより抽象的に定義することができます。Deep Learningするためのプログラムはプログラマーが予め作って置かなければなりませんが、個々の機能を果たすプログラムを個別に作る必要はありません。プログラマーが特定の用途に応じたプログラムを作る変わりに、似たような入力と出力のパターンを大量に読み込ませる(学ばせる)ことで、その機能をもつプログラム(関数)を自動的に作り出すことができます。入力データに対応する出力データを導き出すロジックを明確にする必要はありません。大量の前例から帰納的に導き出すことができるからです。
少し話が抽象的になってしまったので、少し具体的な話をしてみよう。
自動運転のアルゴリズムは実装可能か?
自動車を運転する時の人の動きを追ってみましょう。
- 座席に乗り込み、
- エンジンを始動し、ギアをドライブに入れる。
- 前方に危険がないかを確認し、ブレーキをはなしアクセルを踏む。
- 速度に注意しながらアクセルを調整し、
- 行きたい方向を確認しながらハンドルを切る。
- 信号を確認し赤信号ならば、ブレーキを踏んで、
- 停止線か前方の車の直後で止まる。
- 青信号になったら、また3.に戻る。
3.以降をAIが担当すると仮定して、これを実現するにはどのようにプログラムすることになるのか、少し考えてみましょう。
| id | 入力 | 出力 |
|---|---|---|
| 3. | 前方を確認し | アクセルを踏む |
| 4. | 速度をみて | アクセルを調整する |
| 5. | 行きたい方向を見て | ハンドルを切る |
| 6. | 赤信号を確認して | ブレーキを踏む |
| 7. | 停止線か前方の車の距離を確認して | ブレーキを踏む |
| 8. | 青信号を確認して | 3.に戻る |
基本的に自動車の運転の時、入力データは視覚に頼ることがほとんです。すなわちデジタル・ビデオカメラを360度の視野角で設置すれば、判断に必要な情報は全て揃うということになります。デジタルカメラからのデータをデジタルデータに変換可能であることは言わずもがな理解できます。
そして出力データはアクセル、ブレーキ、ハンドルを、それぞれ数十段階で調整できれば、十分ではないかと思われます。仮に、それぞれ100段階で調整ができたとして、 パターンの識別子があれば、車を自在に操るのに十分な出力データの信号を表現することができます。
この入力データに対する出力データを導くプログラムもしくは関数さえあれば、原理的に自動運転技術は完成します。
これを演繹的AIで実現させようとした場合(すなわち、Deep Learningの技術を使わない場合)、このプログラムを人間(プログラマー)の手で作り出さなければなりません。 デジタル・ビデオカメラで得られた情報は、コンピュータにとっては無味乾燥な01信号であり、まずこれらの01信号を景色として有機的な解釈が必要になります。すなわちその解釈をするプログラムを作らなければならなりません。自動車がまったく同じ道を走ったとしても、雨の時、晴れの時、朝、昼、夜等によっても入力データは異なる形で表現されます。そのバリエーションは天文学的なパターンになることは比較的簡単な計算で予想ができます。赤信号と赤いランドセルをしょった女の子を見分けるだけでも大変なプログラムが必要であり、これは、演繹的アルゴリズムによって自動運転するソフトウェアを人間の手で開発することが現実的には不可能であることを意味しています。
条件反射→パブロフの犬
条件反射(じょうけんはんしゃ)とは、動物において、訓練や経験によって後天的に獲得される反射行動のこと。
(by wikipedia)
旧ソビエトの生理学者イワン・パブロフは、メトロノームを鳴らした後、犬に餌を与えることを繰り返すことで、例え餌を与えなくても、メトロノームを流すだけで、その犬が唾液を出すことを観測し、条件反射というものを定義付けました。
車の運転はパブロフの犬のような生理学的な意味での条件反射とは違いますが、目から得られる決められた条件(入力)によって手足を反応(出力)させるという点においては、抽象的に類似するところがあります。
メトロノームの音は特定のタイミングで特定の周波数の音波を作り出すことで得られ、まったく同じでないにしても概ね同じようなタイミングで同じような周波数の音波を作り出すことは可能であり、これをパブロフの犬は耳の鼓膜で捉え、脳に伝えられた電気信号から、一回づつの音色が完全に同じでなかったとしても、概ね同じであれば、メトロノームの音として解釈して、唾液を出すような指示を脳が送り出します。 パブロフの犬は、メトロノームの概念を知らないだろうし、特定の周波数で空気が震えて、それが鼓膜を揺らして、脳がそれを解釈して、論理的、演繹的に考えて、さあ唾液を出す時が来た、などと意識して行動するはずもありませんが、とにかく、パブロフの犬の脳に存在する脳神経細胞のネットワーク(ニューラルネットワック)が鼓膜で捉えた特定の入力情報から、唾液を出すという出力結果を繰り返しの学習により学んだのです。
Deep Learningはこのような技術の応用といえます。
帰納的方法による自動運転の実装
先程の自動運転の車の例にもどります。 例えば、ドライブレコーダーで、ある無事故無違反のタクシードライバーの運転を1年間録画して、その時々のアクセル、ブレーキ、ハンドルの捜査も(デジタルデータで)記録したとします。
これは一種の写像を形成することになります。
単純にするために、入力データを1000 x 1000すなわち100万画素のデジカメで0.1秒に1回づつ撮影したものとします。1画素あたりRGBをそれぞれ8bitづつ割り当てたとすると1枚の画像につき(非圧縮で)、
24bits (= 3bytes) x 1M = 3M bytes
の入力データを得ます。1画素はint(32bit)整数値で表現可能なため、この1つの入力データを整数が100M個込合わさったものとみなすと の要素のベクトル値と考えることができます。
一方出力データは、アクセル、ブレーキ、ハンドルを1~100の百段階で分けて数値表現するとすると の要素と考えることができます。
すなわちデジカメから捉えたデータからアクセル、ブレーキ、ハンドルを適切に捜査するための信号を算出する関数(写像)を とするとその定義域、値域は
となります。
数学的な表現を使うと
となります。
より正確にいうならば、自動運転のような連続的な状況(入力)から次の行動(出力)を決めなければならない場合には、その瞬間のデータだけでは不十分であり、直前の入力データおよび直前の出力データから次の出力を決める必要があるのですが、ここでは簡略化のためこのようなシンプルなモデルを設定しています。
この関数をどのようなアルゴリズムで実装すればよいのでしょうか?
実はこの多次元ベクトル関数の形はどんな形(アルゴリズム)であるかを考える必要はありません 。ロジックとして厳格である必要はなく、概ね車の運転とは似たような場面で似たようなことをすればよいからです。 すなわち、先程例に出したタクシードライバーの1年間のドライブ記録からこの関数 を導き出して、実際に走る際にデジカメから得た入力データをこの関数 で変換し、アクセル、ブレーキ、ハンドルに電気信号として送ることができれば、概ね車は正しく動いてくれるはずです。この概ねという部分がポイントで、元来コンピュータは離散的0,1信号の集合を厳格な論理回路で処理する特性上、正確さというメリットを得ます。その反面、応用がきかないというデメリットを持っていましたが、Deep Learningはこの厳格さを諦めることで、応用力という大きな武器を手に入れたのです。